
Introduction
Gone are the days of proprietary software and technologies. As AI becomes more democratized, open-source models are gaining momentum. You must have heard of DeepSeek—a Chinese AGI (artificial general intelligence) startup that has made it to the headlines in the last few weeks. It’s everywhere, from social media to developer community forums.

Pushing boundaries in deep learning (DL) and knowledge discovery, DeepSeek’s LLM is more than just another addition to the open-source AI ecosystem. It has challenged other proprietary models by providing 100% transparency at just a fraction of the budget.
What has added more to this buzz is the fact that it has been developed by a Chinese startup (DeepSeek Artificial Intelligence Co., Ltd.). With offerings and capabilities comparable to leading Western models like OpenAI’s ChatGPT, it has captured significant attention, caused people to doubt the actual cost of AI/ML development, and raised concerns over U.S. AI supremacy. This has paved the way for more affordable and accessible AI. Let’s explore what this development has to offer and whether it is an improvement over existing AI market leaders like ChatGPT.
The DeepSeek Hype: Why is Everyone Talking About it?
Visibly, DeepSeek has sparked significant conversations in the AI community.
As per Microsoft’s CEO Satya Nadela, people should have an optimistic view of this development. He wrote, “Jevons paradox strikes again—As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can’t get enough of.”
Similarly, former Intel CEO Pat Gelsinger sees DeepSeek as a reminder of computing’s evolution, emphasizing that cheaper AI will drive broader adoption, constraints fuel innovation (Chinese engineers worked with limited computing power), and most importantly, “open wins”—challenging the increasingly closed AI ecosystem.
However, not everyone is convinced. Elon Musk and Scale AI’s Alexandr Wang remain skeptical, questioning whether DeepSeek’s claims about building a competitive model with minimal computing resources can genuinely be validated. The debate will continue for some time, at least till we find answers to:
- Is DeepSeek really a breakthrough or just an illusion of efficiency?
- Do you need that much compute for building and training AI/ML models?
- Have companies like OpenAI, Google, Amazon, etc., been overpaying?
- Are Nvidia processing chips really central to development?
Inside DeepSeek: What Powers This Open-Source LLM
Architecture
DeepSeek is built on a Mixture-of-Experts (MoE) architecture. In this neural network design, numerous expert models (sub-networks) handle different tasks/tokens, but only selective ones are activated (using gating mechanisms) at a time based on the input.
Model Parameters
The latest model, DeepSeek V3, has been trained on 671 billion parameters with 37 billion activated per token.
Training
It underwent pre-training on a vast dataset of 14.8 trillion tokens, encompassing multiple languages with a focus on English and Chinese. Subsequent supervised fine-tuning (SFT) was conducted on 1.5 million samples, covering both reasoning (math, programming, logic) and non-reasoning tasks. Reinforcement learning was also applied to enhance the model’s reasoning capabilities. (source)
Evaluation Benchmarks
DeepSeek (V3 in particular) tops the leaderboard of all open-source LLMs for the following benchmarks:
| Category | Benchmark |
|---|---|
| English | MMLU (EM), MMLU-Redux (EM), MMLU-Pro (EM), DROP (3-shot F1), IF-Eval (Prompt Strict), GPQA-Diamond (Pass@1), SimpleQA (Correct), FRAMES (Acc.), LongBench v2 (Acc.) |
| Chinese | C-Eval (EM), C-SimpleQA (Correct), CLUEWSC (EM) |
| Math | MATH-500 (EM), CNMO 2024 (Pass@1), AIME 2024 (Pass@1) |
| Code | HumanEval-Mul (Pass@1), LiveCodeBench (Pass@1-COT), LiveCodeBench (Pass@1), Codeforces (Percentile), SWE Verified (Resolved), Aider-Edit (Acc.), Aider-Polyglot (Acc.) |
DeepSeek vs. Competitors: A Feature-by-Feature AI Model Comparison
As DeepSeek has started gaining attention, compared to global tech leaders like Microsoft, Intel, and even OpenAI, an obvious question arises—is it better than others? While it is too soon to answer this question, let’s look at DeepSeek V3 against a few other AI language models to get an idea.
DeepSeek V3 vs. ChatGPT-4 Turbo
Access and Availability
One of the main differences is availability. DeepSeek has made its LLMs fully open-source, allowing developers to fine-tune, modify, and deploy them without any compliance restrictions. ChatGPT, on the other hand, remains a closed-source model controlled by OpenAI, limiting customization for users and researchers.
Training Data & Model Architecture
As mentioned above, DeepSeek’s latest model has been trained on 671 billion tokens. However, information on the training data of OpenAI’s latest model, ChatGPT-4 Turbo, is not publicly available. It is rumored to be trained on 1.76 trillion parameters! Additionally, the latter is based on a DNN (deep neural network) that uses a transformer architecture.
Performance Benchmarks
While data on DeepSeek’s performance on industry benchmarks has been publicly available since the start, OpenAI has only recently released it for a few benchmarks: GPT-4 Preview, Turbo, and 4o. Here is the crux of the matter.
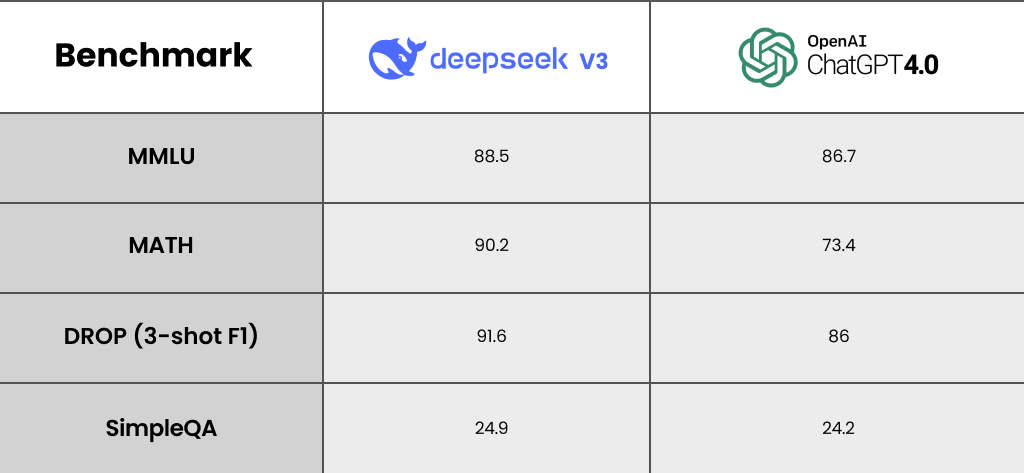
Multilingual Capabilities
Both LLMs support multiple languages, but DeepSeek is more optimized for English and Chinese-language reasoning. Currently, ChatGPT has stronger multilingual fluency across a broader range of languages.
Computational Efficiency
DeepSeek’s LLMs are based on an MoE architecture that enables better efficiency by activating only relevant parameters, reducing unnecessary computational overhead. In contrast, ChatGPT’s full-parameter model requires significantly more resources, making large-scale deployments slightly costlier. However, with custom training and integration, ChatGPT can be optimized.

DeepSeek V3 vs. Claude 3.5 Sonnet
Claude 3.5 Sonnet is another reputed LLM developed and maintained by Anthropic. Let’s see how DeepSeek stands against it.
Access and Availability
While V3 is publicly available, Claude 3.5 Sonnet is a closed-source model accessible through APIs like Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI.
Training Data & Model Architecture
3.5 Sonnet is based on a GPT (generative pre-trained transformer) model. Further details about training data are proprietary and not publicly disclosed. However, it is rumored to be trained using 137 billion text and code parameters.
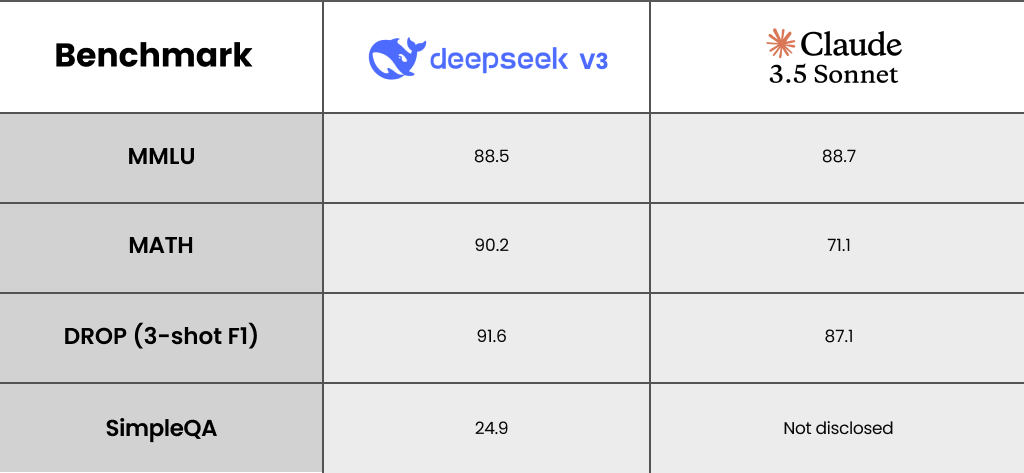
Performance Benchmarks
Like DeepSeek, Anthropic has also released Claude 3.5 Sonnet’s performance data.
Multilingual Capabilities
While DeepSeek focuses on English and Chinese, 3.5 Sonnet was designed for broad multilingual fluency and to cater to a wide range of languages and contexts.
Computational Efficiency
DeepSeek V3 is computationally efficient, achieving targeted activation based on desired tasks without incurring hefty costs. Similarly, even 3.5 Sonnet claims to offer efficient computing capabilities, particularly for coding and agentic tasks.
DeepSeek V3 vs. Gemini 2.0
Google DeepMind’s Gemini is another widely used AI model. It has strong backing from Google’s vast ecosystem of applications to build its logical reasoning, making it efficient for a variety of tasks, including those related to natural image, audio, and video understanding and mathematical reasoning. Let’s see how it compares to V3.
Access and Availability
While V3 is a publicly available model, Gemini 2.0 Flash (experimental) is a closed-source model accessible through platforms like Google AI Studio and Vertex AI.
Training Data & Model Architecture
Details about Gemini’s specific training data are proprietary and not publicly disclosed. It, however, is a family of various multimodal AI models, similar to an MoE architecture (identical to DeepSeek’s).
Performance Benchmarks
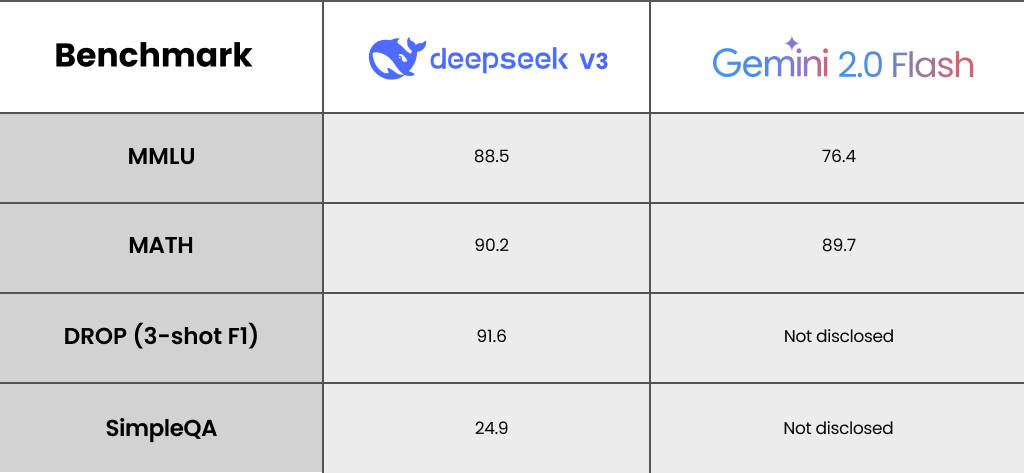
Multilingual Capabilities
Gemini 2.0 Flash is also designed to provide contextual multilingual support.
Computational Efficiency
Gemini 2.0 Flash is designed for speed and efficiency, particularly in real-time applications that require multimodal AI processing. Due to native tool integration, it can directly call Google Search, execute code, and use many other third-party functions within the model itself, reducing redundant computation by pulling external data.

DeepSeek’s Growth: A Technological Leap or a Looming Threat?
DeepSeek’s entry has shaken the AI market, a segment traditionally dominated by the U.S. It has not only gained popularity but also become the top-rated free application on Apple’s App Store, surpassing ChatGPT.
This development has also extended the shock waves beyond this industry to even the financial markets. When the Chinese AI startup claimed to have not relied on costly computing, Nvidia’s stock plummeted nearly 17% to 18% (now close to 20% as reported by Bloomberg and Yahoo Finance), erasing billions of US$ in market value! Investors across the world have started reevaluating their strategies.
While it has caused an AI power shift toward the East, it has also exposed the new AI model to security challenges. On January 30, 2025, a major data breach exposed over a million log lines, including chat histories, secret keys, and backend data. This breach didn’t just expose user data; it also reminds us of an uphill battle that new AI companies face in keeping their systems secure.
What to Expect in The Future?
These developments have only heightened concerns and scrutiny from global stakeholders. While some applaud DeepSeek’s rapid progress, others are wary of the risks—the spread of misinformation, security vulnerabilities, and China’s growing influence in AI. Until DeepSeek officially discloses how it achieved this breakthrough, speculation will continue, and so will the debates around its impact.
Even if those answers come, DeepSeek has cemented itself as a serious contender in the AI race. One thing, however, is sure: a typical journey in the foundational AI segment is a complex interplay between innovation, competition, and scrutiny. If you’re looking to enter this space with your own AI/ML model, be prepared to face it all—the breakthroughs, the challenges, and the inevitable scrutiny that comes with AI breakthroughs.
Ready to begin? Having the right expertise and support from a reliable partner can make all the difference here. From model training and optimization to data engineering and deployment, our AI developers can give you the desired support. Contact us today.

